
I recently launched https://report-uri.io, my new CSP and HPKP violation reporting service that is built on, amongst other things, Azure Table Storage. Using Table Storage required a little bit of a shift in thinking and works in slightly different ways compared to your traditional RDBMS. In this blog I'm going to look at some of those differences and how I came to leverage the full potential of the service.
Introduction
Table Storage is a NoSQL key value store. You can simply insert data with a key to look it up on and return to fetch the data back out at a later time. In terms of features, it doesn't really get much more advanced than that and it does take a little getting used to. That said, once I'd adapted and learnt the best way to leverage Table Storage, you can do some pretty awesome things.
![]()
Table Storage Basics
Before I delve into some of the technical details of Table Storage, let me give a quick overview of what the service is and how it works. I'm using Table Storage with the PHP SDK and there is some great documentation on the Azure site for details on how to get started with PHP or .NET depending on your taste. The Table Storage Data Model is also worth a read and outlines details like restrictions on table names, property names, system properties and much more. Here is the basic layout of how I'm using Table Storage for https://report-uri.io:
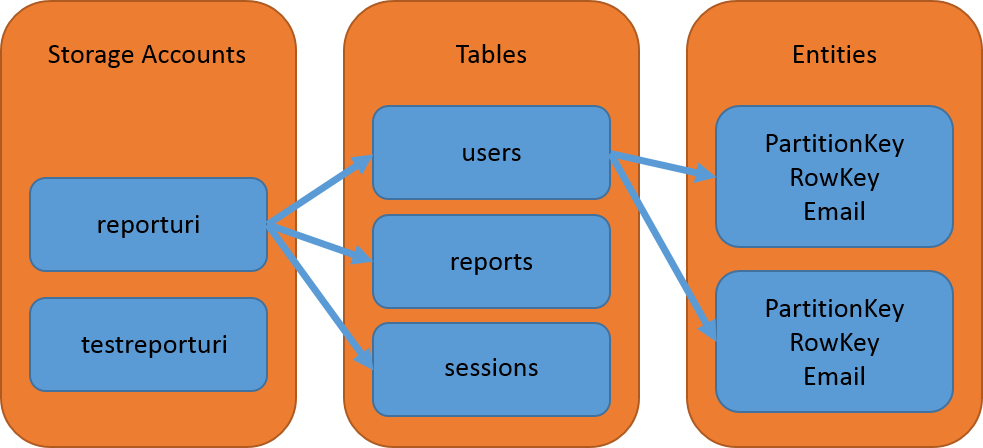
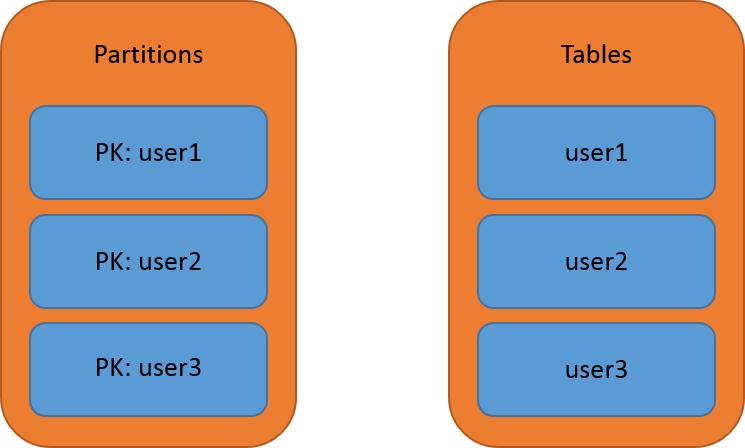
I have 2 storage accounts so the production site and the development site can operate totally independent of each other. Within your storage account you have tables to store your data in, much like a typical RDBMS. These tables don't have a fixed schema though and you can't control which 'columns', or properties in this case, are indexed. The PartitionKey and RowKey values are the only indexed keys in the table and they are used to create a clustered index for fast querying. A table itself can be made up of many partitions and a good example of that might be something like the following:
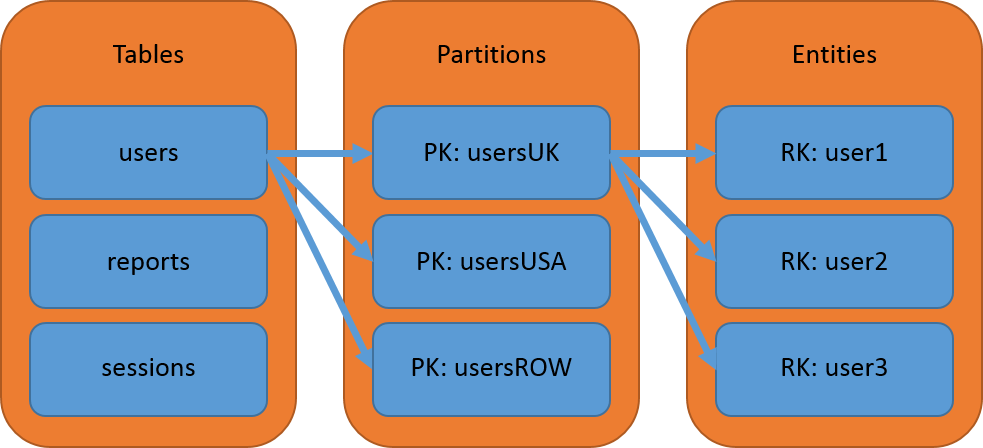
Fast Querying
The fastest way to query an entity out of Table Storage is using the combination of its PartitionKey and RowKey. As the only indexed properties, the PartitionKey narrows down the query from the entire table to just the specific partition where the entity resides and the RowKey allows the query to identify the specific entity itself within the partition. Within a table, each PartitionKey and RowKey combination have to be unique and in the scenario above we could expect to lookup a user in mere milliseconds.

The getEntity() method takes the table name, PartitionKey and RowKey as parameters and returns the specified entity if it exists. If not, a ServiceException is thrown with the error code 404 and message 'ResourceNotFound'. The next step down is to lookup an entity without knowing the RowKey but using the PartitionKey and another property of the entity.

The queryEntities() method takes the table name and a filter string to search with and returns any entities that match the filter. If none are found it returns an empty set and does not throw an exception. This query is slightly slower as it has to scan the entire partition and check the email property of each entity. The worst case scenario is a query that doesn't use either the PartitionKey or the RowKey in the search as this requires a full table scan to find the entity you want.
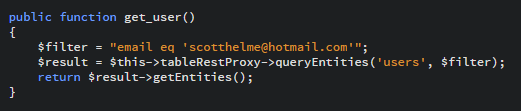
This query will have to scan over every single entity in the user table and match it against the criteria for the email property. These types of queries are best avoided and if the results of the query are found in different partitions, the Table Storage service will issue you a continuation token and you will have to return to fetch the rest of the results from each partition. More on that later on.
Fast Inserting
Whilst there are less considerations for how fast we can bung data into the service compared to how fast we can pull data out, there is still something that we should consider. The Azure Storage Scalability and Performance Targets state that a standard storage account in a US region can handle up to 20,000 entity requests per second. If we dig a little deeper though, we can see that there is a 2,000 entities per second throughput limit on each table partition (and this applies to reads and writes). Now, that might not be such a big problem in the context of our user table example above, but if you're expecting a partition to be able to handle a large volume of transactions, an approach that breaks data down instead of say one large generic 'users' partition is much preferred.
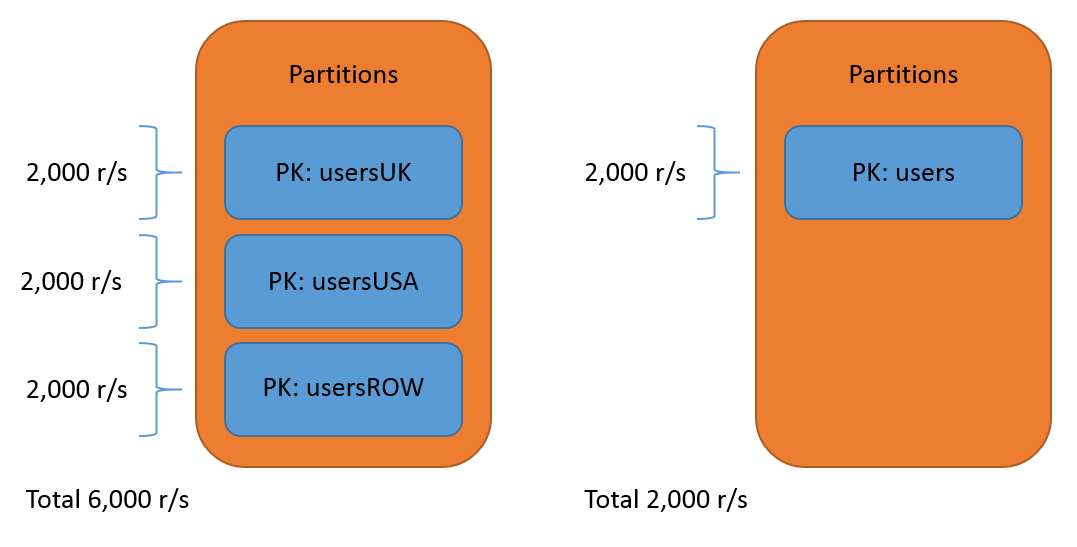
This is to do with how Azure load balances requests against the table and partitions within that table. Because partitions are logical chunks of data, Azure will load balance a partition with high volumes of traffic by moving it to a different server. This allows the partition to serve the demands being placed upon it and not adversely affect other partitions that used to reside on the same box.
Fast Deleting
Another factor to bear in mind is how you can delete entities from Table Storage. You can either delete an entity by calling the deleteEntity() method and passing in the table name, PartitionKey and RowKey, or you can delete an entire table and all entities within it. That's it. For report-uri.io there was the potential for a huge amount of reports to be collected per user. Initially I was planning to use a reports table and have a unique partition for each user, but that didn't give me enough granularity for my queries. The other issue that presented me was how to delete a user's data should they wish to remove everything. If they had their own partition this would mean querying out every single entity in the partition to delete it. Not only would that take longer than I'd care to think and incur some cost, it's a really ineffective way of deleting that much data. This lead me to creating a unique table for each user and storing all of their data in that. Now, should a user wish to delete all of their data from the service, all I have to do is drop the table. Not only that, but it meant that I could free up my PartitionKey to be used to break data down with a time stamp value for more efficient querying later on.
Fast Updating
Like a delete operation, an update operation requires you to identify an entity using its PartitionKey and RowKey. If you can't or don't know these 2 values then you will need to search for the entity using other criteria, hopefully with at least the PartitionKey to prevent a full table scan. Beyond this, the same performance targets apply as previously mentioned and the only way that you can further increase performance is using Entity Group Transactions.
Entity Group Transactions
EGTs are a great way of increasing the performance of queries when you are performing multiple operations within the same partition. Rather than performing several operations, including insert, delete, merge and update, as sequential calls to the Table Storage service, you can group up to 100 operations together to be executed as a batch. You can't make more than 1 change to the same entity within a batch operation, and other than the requirement that all entities are in the same partition, there are no further restrictions.
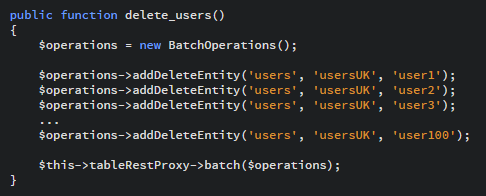
Just removing 99 of the 100 HTTP round trips to the Table Storage service is a significant performance saving in itself but there is also an added cost saving too. The single batch will be charged as 1 single transaction against the Table Storage service and in this particular example would reduce the transaction cost of these delete operations by 99%!
More To Come
This is just the first post in what will probably be a series of blogs on using Azure Table Storage. There are a great many things I've learnt along the way and problems I've had to resolve. I'm going to open up some of my source on GitHub and hopefully I can get some feedback on my implementation too.